


Does artificial intelligence just need more data?
Algorithms based on neural networks keep improving with more training data. Will they ever reach a limit? And is more data alone enough for an AI to one day be comparable with a human brain?


In a September interview, Anthropic CEO and cofounder Dario Amodei suggested that there is no limit to the amount of data that can be ingested to improve the training of large language models using neural networks. He also hinted that there may be no limits at all to their future capabilities.
From the article:
Speaking onstage at TechCrunch Disrupt, Amodei explained that he doesn't see any barriers on the horizon for his company's key technology.
"The last 10 years, there's been this remarkable increase in the scale that we've used to train neural nets and we keep scaling them up, and they keep working better and better," he said. "That's the basis of my feeling that what we're going to see in the next 2, 3, 4 years... what we see today is going to pale in comparison to that."[1]
That models based on neural networks continue to improve with more data is what differentiates deep learning from classical machine learning. Classical machine learning algorithms typically reach a performance limit where adding more data does not produce any significant improvement in the model’s predictive power. So far, no such limit has been found with algorithms built using neural networks. The more data they ingest, the more their output improves.
A bigger debate is brewing about whether or not a sufficiently large LLM will achieve artificial general intelligence (AGI). LLMs have demonstrated a step towards that potential by generalising and performing a variety of language-based tasks that they were not specifically trained for. For example, supplying a text and asking the LLM to “summarise the text in the style of a pirate” without first training the model to recognise and reproduce text in the style of a pirate:
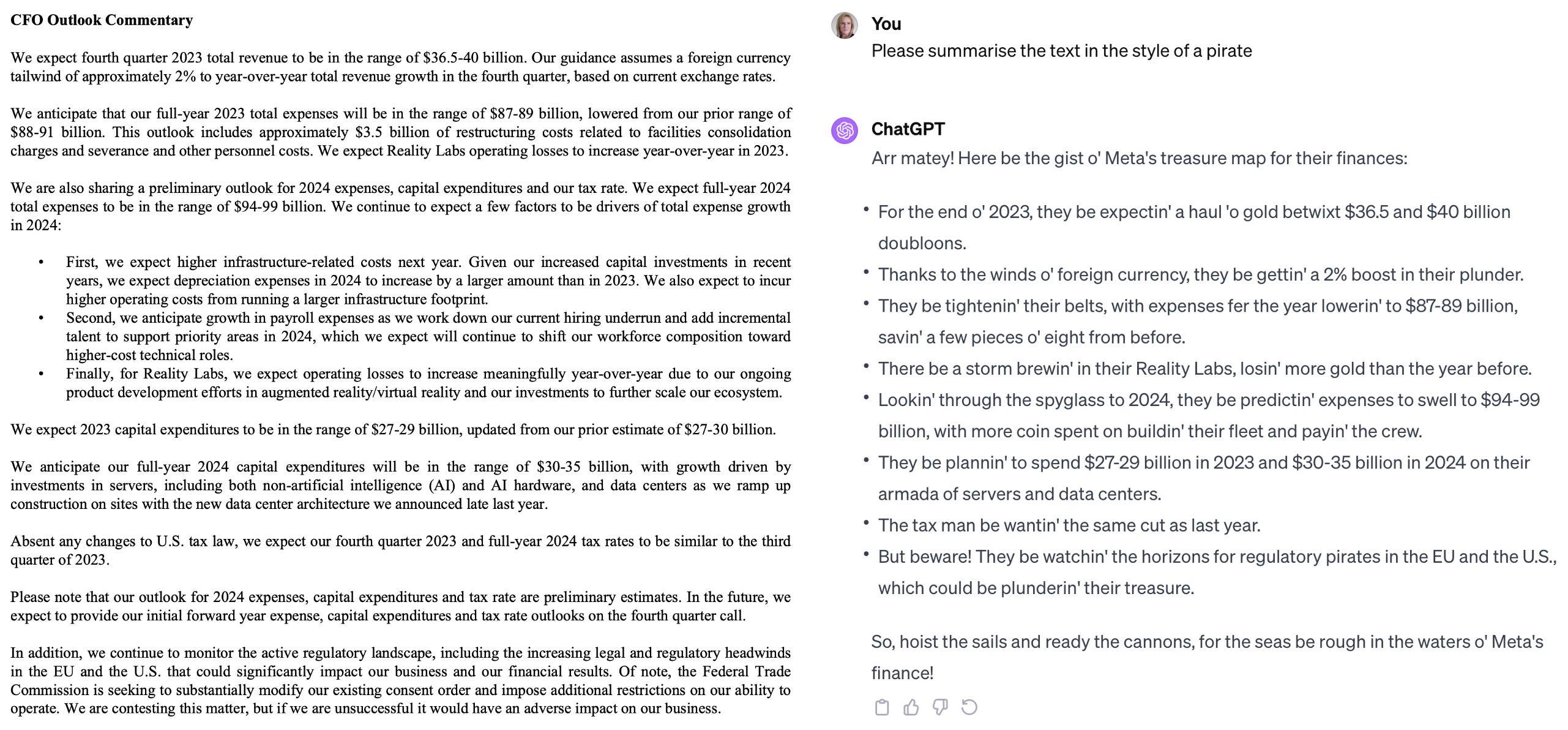
Back to the interview with Amodei:
Some researchers have suggested, however, that no matter how large these transformer-based models get, they may still find certain tasks difficult, if not impossible… “Do you think that we should be trying to identify those sort of fundamental limits?" asked the moderator (myself).
"Yeah, so I'm not sure there are any," Amodei responded. "And also, to the extent that there are, I'm not sure that there's a good way to measure them. I think those long years of scaling experience have taught me to be very skeptical, but also skeptical of the claim that an LLM can't do anything.”[1]
Unsurprisingly, there are plenty who would disagree that a LLM could ultimately be capable of performing any text-based task. Over on LinkedIn, Paul Burchard shared this interview with his perspective, that assuming further scaling of LLMs will be sufficient without needing to understand what intelligence is deeply flawed, providing 4 examples (summarised here):
1. Infeasibility of Brute Force.
Many interesting problems are high dimensional where the compute effort to solve using data alone scales exponentially. To solve practically must incorporate some kind of human ingenuity.
2. Vast Undervaluation of Cost of Data.
High quality data is now, and has always been, difficult and expensive to create.
3. Vastly Uneconomic Use of Compute.
The human brain, running on 20 Watts, still beats out attempts at brute force AI algorithms, which require Megawatts to run, for many problems
4. Catastrophic Failure to Solve the Problem.
Such models, having no actual intelligence of their own, will inevitably be asked to perform outside of their training data, at which point they will fail catastrophically.[2]
It adopts a much more pragmatic approach to the use of generative AI, considering when it is and isn’t practical to use from a resource cost perspective and risk perspective. Cory Doctorow has also focused on these angles, arguing that AI will enter another winter if investments do not convert into high-value risk-tolerant applications:
Live, large-scale Big Tech AI projects are shockingly expensive to run. Some of their costs are fixed – collecting, labeling and processing training data – but the running costs for each query are prodigious. There's a massive primary energy bill for the servers, a nearly as large energy bill for the chillers, and a titanic wage bill for the specialized technical staff involved.
Once investor subsidies dry up, will the real-world, non-hyperbolic applications for AI be enough to cover these running costs? AI applications can be plotted on a 2X2 grid whose axes are "value" (how much customers will pay for them) and "risk tolerance" (how perfect the product needs to be).
The problem for AI is that while there are a lot of risk-tolerant applications, they're almost all low-value; while nearly all the high-value applications are risk-intolerant. Once AI has to be profitable – once investors withdraw their subsidies from money-losing ventures – the risk-tolerant applications need to be sufficient to run those tremendously expensive servers… [3]
Barchard’s fourth example reminded me of an interview with computer scientist Michael Jordan in 2014. Aside from the first sentence, the opening statement from the article has not aged well…
The overeager adoption of big data is likely to result in catastrophes of analysis comparable to a national epidemic of collapsing bridges. Hardware designers creating chips based on the human brain are engaged in a faith-based undertaking likely to prove a fool’s errand. Despite recent claims to the contrary, we are no further along with computer vision than we were with physics when Isaac Newton sat under his apple tree.[4]
So it turned out that those hardware designers weren’t on such a fool’s errand after all, as Nvidia’s stock price rise during 2023 showed… However, that first sentence very much aligns with the perspectives Barchard and Doctorow aired a decade later - that over reliance on data-driven automation will lead to catastrophic failures. It has certainly been the case with self-driving cars recently. The article remains a great read and reminder that we tend to make flawed comparisons between brain intelligence and artificial intelligence:
Michael Jordan: Specifically on the topic of deep learning, it’s largely a rebranding of neural networks, … people continue to infer that something involving neuroscience is behind it, and that deep learning is taking advantage of an understanding of how the brain processes information, learns, makes decisions, or copes with large amounts of data. And that is just patently false.
Spectrum: If you could, would you declare a ban on using the biology of the brain as a model in computation?
Michael Jordan: No. You should get inspiration from wherever you can get it. As I alluded to before, back in the 1980s, it was actually helpful to say, “Let’s move out of the sequential, von Neumann paradigm and think more about highly parallel systems.” But in this current era, where it’s clear that the detailed processing the brain is doing is not informing algorithmic process, I think it’s inappropriate to use the brain to make claims about what we’ve achieved. We don’t know how the brain processes visual information.[4]
There is still much we do not understand about how the human brain works. An artificial neural network is based crudely on just one aspect of brain function. But back to Amodei’s point of view - does that matter? Is it enough that the AI models just keep getting better with more data? This argument was first made back in 2008, in a controversial article published in Wired Magazine - The End of Theory: The Data Deluge Makes the Scientific Method Obsolete:
Scientists are trained to recognize that correlation is not causation, that no conclusions should be drawn simply on the basis of correlation between X and Y (it could just be a coincidence). Instead, you must understand the underlying mechanisms that connect the two. Once you have a model, you can connect the data sets with confidence. Data without a model is just noise.
But faced with massive data, this approach to science — hypothesize, model, test — is becoming obsolete. …Petabytes allow us to say: "Correlation is enough." We can stop looking for models. We can analyze the data without hypotheses about what it might show. We can throw the numbers into the biggest computing clusters the world has ever seen and let statistical algorithms find patterns where science cannot.[5]
Arguably, this is what the Alpha series of models has been achieving, most recently with AlphaFold’s breakthrough in protein-folding. In an interview talking about the success of AlphaFold, Demis Hassabis said something that has stuck with me:
Machine learning is the perfect description language for biology in the same way that maths was the perfect description language for Physics. [6]
Hassabis went on to found a new company based on this principle - Isomorphic. The argument is that biology shares more in common with information processing than with mathematics. [7] It leans towards the argument that data now trumps theory…
What’s also interesting, on re-listening to the podcast to retrieve the quote, is that, in March 2022, Hassabis was describing how we were still a long way from having generalisable language models:
We have some language models. But they don’t have a deep understanding yet still of concepts that underlie language. And so they can’t generalise or write a novel or make something new. [6]
Less than a year later, novels written using LLMs were being published on Amazon. [8]
The point for this ramble through opinions expressed over the past 15 years regarding the potential and pitfalls of big data and AI is that we still just don’t know how far we can get, in terms of behaviours we would consider as intelligent, using artificial means. We continue to make claims something is impossible or decades away, only for a breakthrough to occur just months later that makes the impossible possible. But there are also plenty of human capabilities and behaviours that are today beyond the reach of AI and that may always be the case.
I think the constant comparison with human brain function risks distracting from the truly fascinating breakthroughs in AI algorithms that have occurred over the past decade, and in particular within the past 3 years with large language models and computer vision. Instead, perhaps we should be wondering what new intelligence is possible through artificial means that a human cannot perform, and vice versa, and consider how those two different world views combine and complement one another. Human-augmented AI and AI-augmented human offers a far more exciting future than simply trying to use AI to replace and automate human intelligence.
References
Anthropic's Dario Amodei on AI's limits: 'I'm not sure there are any,' by Devin Coldewey, 21 September 2023. https://finance.yahoo.com/news/anthropics-dario-amodei-ais-limits-184557981.html
LinkedIn opinion on the article by Paul Burchard, 4 January 2024. https://www.linkedin.com/posts/paulburchard_anthropics-dario-amodei-on-ais-limits-activity-7148414753793601536-mqdv/
What Kind of Bubble is AI? by Cory Doctorow, https://pluralistic.net/2023/12/19/bubblenomics/
Machine-learning maestro Michael Jordan on the delusions of big data and other huge engineering efforts, by Lee Gomes, 20 October 2014, IEEE Spectrum. https://spectrum.ieee.org/machinelearning-maestro-michael-jordan-on-the-delusions-of-big-data-and-other-huge-engineering-efforts
The End of Theory: The Data Deluge Makes the Scientific Method Obsolete, by Chris Anderson, 23 June 2008. https://www.wired.com/2008/06/pb-theory/
DeepMind: The Podcast - Series 2, Episode 9: The Promise of AI, 15 March 2022. https://deepmind.google/discover/the-podcast/
Introducing Isomorphic Labs, by Demis Hassabis, 1 November 2022. https://www.isomorphiclabs.com/articles/introducing-isomorphic-labs
ChatGPT launches boom in AI-written e-books on Amazon, by Greg Bensinger, 21 February 2023. https://www.reuters.com/technology/chatgpt-launches-boom-ai-written-e-books-amazon-2023-02-21/
Opening image generated by ChatGPT-4 based on the text of the article byline.